Catalog Optimization
Catalog Optimization for AI Platforms: The Ultimate Guide
How to enrich every SKU with structured attributes, schema markup, and contextual metadata so AI shopping assistants accurately parse, compare, and recommend your products at scale.

Sakshi Gupta






Key Takeaways
Retailers cited most often by AI shopping assistants share detailed attribute tables, machine-readable specifications, and complete schema.org Product markup at the SKU level - not just page-level descriptions.
AI-referred sessions converted 31% more than other traffic sources in 2025, and AI-driven revenue per visit rose 254% during the holiday season, making catalog quality a direct revenue lever.
Incomplete or inconsistent product data sends a cumulative signal to AI systems that a product is unreliable and not worth recommending - data quality issues already cost organizations 31% of revenue through poor recommendations.
Each technical attribute - weight, dimensions, material, compatibility, color, size - must be a separate PropertyValue entry in schema markup rather than buried in prose, as this is the single highest-leverage change for AI recommendation rates.
Brands managing thousands to millions of SKUs need automated enrichment pipelines (not manual processes) to keep pace with AI shopping channels, where 45% of online shoppers now engage an AI assistant during their purchase journey.
SKU-level catalog optimization for AI is the practice of enriching each individual product record with complete structured attributes, schema markup, and contextual metadata so AI shopping assistants can accurately parse, compare, and recommend that specific SKU. Retailers who invest in this discipline now are building a compounding advantage as AI becomes the dominant discovery channel for commerce.
Why AI Catalog Readiness Is Now a Revenue-Critical Priority
AI shopping channels are growing faster than any prior commerce shift. 45% of online shoppers engaged an AI assistant during their most recent purchase journey as of January 2026, up from just 18% in 2024. Retail saw AI-driven traffic surge 693% year-over-year during the 2025 holiday season, the largest jump of any industry tracked by Adobe. These are not vanity metrics - they represent a structural shift in how purchase decisions are made.
The revenue case is equally clear. AI referrals converted 31% more than other traffic sources, with AI-driven revenue per visit up 254% during the 2025 holiday season. Shoppers arriving from AI assistants were also 33% less likely to bounce and spent 45% more time on-site. This quality of traffic is unprecedented - and it flows disproportionately to products with the richest, most structured data.
The Agentic Commerce Shift
The next wave goes beyond recommendations. OpenAI's Operator, launched in January 2025, now integrates with ChatGPT via an Agentic Commerce Protocol co-developed with Stripe, allowing users to complete purchases without leaving the chat. Morgan Stanley estimates agentic shoppers could represent $190 billion to $385 billion in U.S. e-commerce spending by 2030. When an AI agent completes a purchase autonomously, the only products it can consider are those with machine-readable, structured data at the SKU level. Catalog quality is no longer a back-office concern - it is a direct determinant of whether your products exist in the AI commerce layer at all.
What Makes a Product Catalog 'AI-Unreadable' - and What Does It Cost?
Incomplete, inconsistent, or unstructured product data creates a cumulative signal to AI systems that a product is unreliable and not worth recommending. Data quality issues affect 31% of organizational revenue through poor recommendations and incorrect decisions. In 2024, 85% of generative AI projects failed to reach production due to incomplete data foundations. The cost of catalog neglect is not abstract - it shows up directly in AI invisibility and lost revenue.
The four failure modes catalog teams must address at the SKU level are:
Missing attributes: Weight, dimensions, material, and compatibility fields left blank or defaulted to generic values.
Inconsistent naming conventions: The same attribute expressed differently across variants ("Blue" vs. "Navy" vs. "Blue/Navy") breaks AI comparison queries.
Prose-buried specifications: Technical details written into paragraph descriptions instead of discrete structured fields - LLMs cannot reliably extract these.
Absent or malformed schema markup: No schema.org Product implementation, or schema that omits the additionalProperty and Offer fields AI systems rely on most.
How to Structure Product Data for AI Recommendation Engines
Structured product data is the single highest-leverage change retailers can make. Retailers cited most often by AI shopping assistants share detailed attribute tables, machine-readable specifications, and complete schema.org Product markup - applied at the SKU level, not just the page level. Leaders like Amazon and Shopify have already applied this approach at scale, enriching tens of millions of SKUs with AI.
Required Schema Fields for AI Citation
Content with proper schema markup shows 30-40% higher visibility in AI-generated answers. The core schema.org fields required for AI citation are:
Product: name, description, brand, sku, gtin, image, url
Offer: price, priceCurrency, availability, seller
AggregateRating: ratingValue, reviewCount - improves citation likelihood significantly
additionalProperty (PropertyValue): each technical attribute as a discrete entry - this is the field AI assistants parse for specification and compatibility queries

Each technical attribute - weight, dimensions, material, voltage, compatibility, color, size - must be a separate PropertyValue entry in the additionalProperty field, not buried in prose descriptions. AI assistants parse structured fields; they do not reliably extract specifications from narrative text. This single change has the highest per-SKU impact on recommendation rates of any optimization action.
Attribute Completeness Standards for LLM Consumption
A complete SKU record for LLM consumption goes beyond basic product information. It must include all technical specifications as discrete fields, variant-level differentiators (each size, color, and configuration as a separate SKU with its own attributes), lifestyle and use-case tags, AggregateRating data, and complete Offer information. Missing any one of these layers reduces an SKU's chance of being cited - especially for comparison queries where AI systems weigh completeness across competing products.
Taxonomy and Naming Consistency
Standardized attribute vocabularies across a catalog matter for faceting, filtering, and AI comparison queries. When an AI assistant compares similar products across vendors, inconsistent naming (Blue vs. Navy vs. Blue/Navy) creates ambiguity that systematically deprioritizes products with non-standard taxonomies. Lock attribute vocabularies at the catalog level, document them in a controlled-vocabulary spec, and enforce consistency at ingest - not after the fact.
AI Catalog Enrichment Tools: A Comparison for Large Retailers
Enterprise catalog teams have several purpose-built platforms to choose from. The table below compares leading enrichment tools across the dimensions that matter most for large-scale AI readiness.
Platform | Enrichment Method | SKU Scale | Data Sources Ingested | Schema Output | PIM/OMS Integration | Enterprise Controls |
|---|---|---|---|---|---|---|
AI enrichment + visibility tracking | Enterprise scale | PDFs, supplier feeds, specs | Full schema.org output | Yes | SOC 2, SSO, AI citation monitoring | |
GroupBy Enrich AI | AI/ML | Enterprise scale | PDFs, images, product data feeds | Schema-ready output | Yes | Enterprise SLAs |
Stylitics | AI/ML, retail-first taxonomy | 200M+ products | Images, supplier data, reviews | Lifestyle + technical tags | Yes | Regional localization |
NVIDIA AI Catalog Enrichment | Multimodal AI (vision + NLP) | Tens of millions of SKUs | Images, PDFs, supplier portals | Attribute tables, schema | API-based | Enterprise GPU infrastructure |
Zoovu | AI/ML + guided selling | Large catalogs | PDFs, images, reviews, supplier portals | Structured attributes | Yes | SOC 2, SSO |
What differentiates Nudge's Catalog Optimizer is its integration with AI search visibility tracking and shoppable funnel conversion in a single platform. Most enrichment tools stop at data output - they don't tell you whether enriched SKUs are actually being cited by AI assistants or converting AI-referred sessions. Nudge closes that loop, giving commerce teams a direct line from catalog data quality to AI citation share to revenue.
How to Build a Scalable SKU Enrichment Pipeline
Manual enrichment is not viable at enterprise scale. Stylitics' AI-powered enrichment engine has enabled over 200 million products for global brands. The only practical path for large retailers is an automated pipeline. Here is the five-stage operational workflow:
Stage 1 - Audit: Use automated scanning to identify SKUs with missing attributes, schema gaps, and variant inconsistencies. Prioritize high-revenue and high-traffic SKUs first. Nudge's AI visibility platform surfaces which SKUs have zero AI citation share, giving the audit a direct revenue lens.
Stage 2 - Ingest: Pull raw data from PDFs, CSVs, supplier portals, product images, and customer reviews into a centralized enrichment layer. Multimodal ingestion - combining text and image sources - captures attributes that exist in one format but not another.
Stage 3 - Enrich: Apply multimodal AI to generate missing attributes, standardize taxonomy, produce schema-ready output, and add lifestyle and use-case tags. This is where platforms like Nudge operate at scale.
Stage 4 - Validate: Apply quality scoring and human-in-the-loop review for high-stakes categories - safety-critical products, luxury items, or categories with high return rates. Automated confidence scoring flags low-certainty attributes for human review.
Stage 5 - Publish and Monitor: Push enriched data to your PIM, commerce stack, and schema layer. Then track AI citation rates and recommendation share at the SKU level using a purpose-built visibility platform. Enrichment without monitoring is a one-time fix, not a sustained advantage.
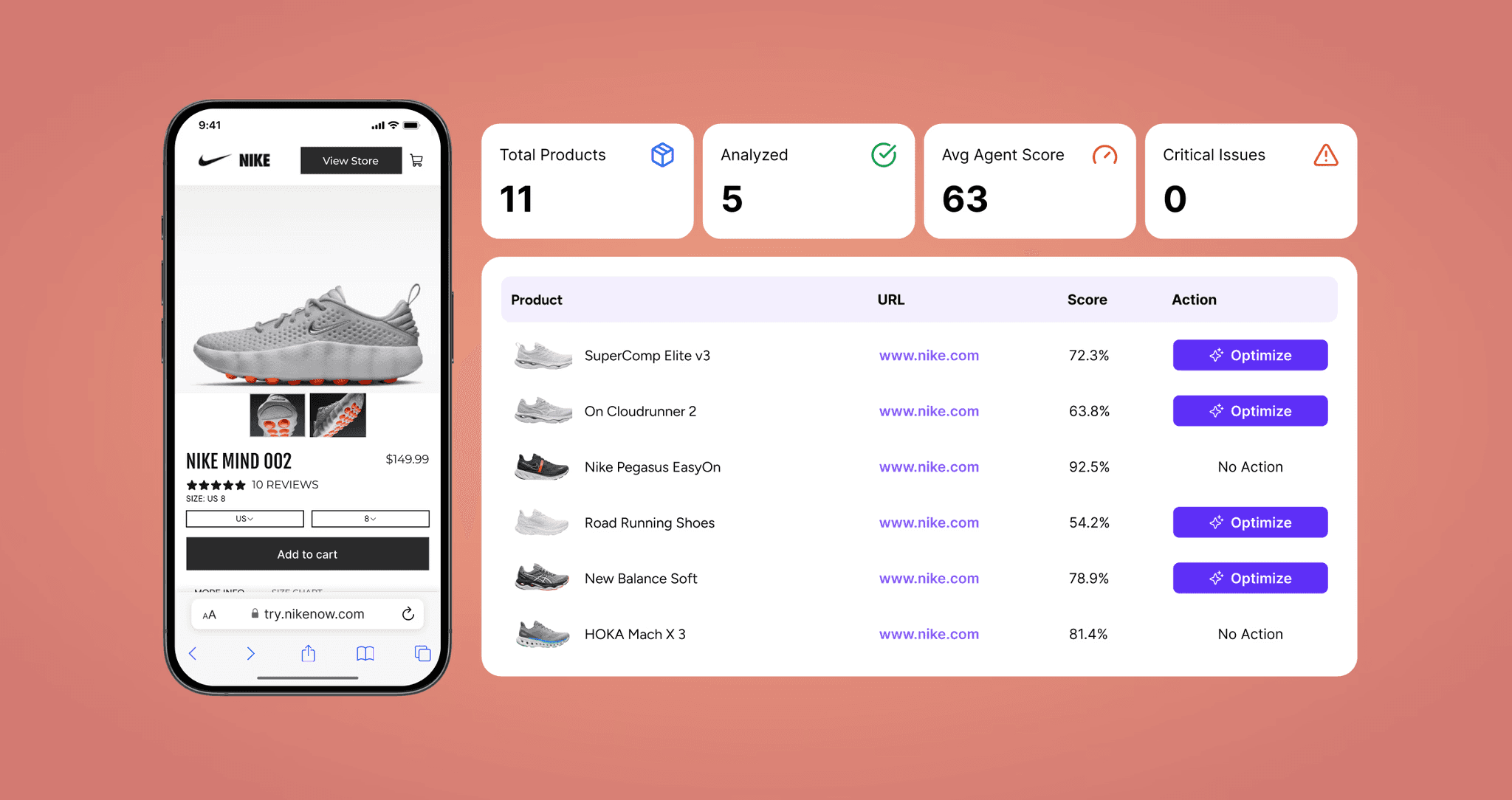
How to Measure Whether Catalog Optimization Is Improving AI Recommendation Rates
Standard analytics tools do not surface AI referral channels or SKU-level citation data - this is the core measurement gap most catalog teams face. Purpose-built AI visibility platforms are required to close the loop between enrichment investment and recommendation outcomes. The KPI framework for AI catalog measurement covers five dimensions:
KPI | What It Measures | Why It Matters |
|---|---|---|
AI Mention Share by SKU | How often a specific product is cited in AI assistant responses | Direct signal of catalog readiness and AI recommendation frequency |
AI-Referred Session Conversion Rate | Conversion rate of sessions originating from AI assistants | Quantifies revenue impact of AI visibility; AI referrals convert 31% higher than average |
Schema Coverage Score | Percentage of SKUs with complete PropertyValue entries | Tracks structural readiness across the catalog; gaps predict AI invisibility |
Attribute Completeness Score | Average number of required attributes present per SKU by category | Identifies enrichment backlog and prioritizes high-impact categories |
Search CTR and Add-to-Cart Post-Enrichment | Change in click and cart rates after enrichment deployment | Validates enrichment quality in on-site discovery as well as AI channels |
The competitive stakes for early movers are significant. 26% of brands had zero mentions in AI Overviews in one industry snapshot, and 47% of brands still lack a deliberate generative engine optimization strategy. Brands that build catalog-to-citation measurement infrastructure now are accumulating recommendation share that compounds as AI shopping volume grows. Nudge's AI Search Visibility platform surfaces SKU-level citation data across ChatGPT, Perplexity, Google AI Overviews, and other major AI shopping surfaces - giving catalog teams the signal they need to prioritize enrichment investment.
Optimize Your Catalog for AI Shopping!
Frequently asked questions
What is SKU-level catalog optimization for AI?
SKU-level catalog optimization for AI is the practice of enriching each individual product record with complete, structured attributes, schema markup, and contextual metadata so AI shopping assistants can accurately parse, compare, and recommend that specific SKU. It is distinct from page-level SEO or bulk catalog management - it operates at the granularity of a single variant, ensuring every size, color, and configuration has its own machine-readable data profile.
Why do AI assistants ignore products with incomplete data?
LLMs rank and recommend products based on the structured signals they can parse. Missing attributes, inconsistent naming, and prose-buried specs create ambiguity that causes AI systems to deprioritize or skip a product entirely. The cumulative effect is invisibility: incomplete data combined with poor quality across channels sends AI systems a clear message that a product is unreliable and not worth recommending. Data quality issues already cost organizations 31% of revenue through poor recommendations.
Which product attributes matter most for AI recommendation engines?
Technical specs (weight, dimensions, material, compatibility), variant-level differentiators (color, size, configuration), use-case and lifestyle tags, and complete schema.org Product markup with additionalProperty entries are the highest-priority attributes. AggregateRating and Offer fields also improve citation likelihood. Each attribute must be a discrete structured field - not buried in a paragraph description - because AI assistants parse structured fields, not narrative text. Content with proper schema markup shows 30-40% higher visibility in AI-generated answers.
How do I measure if catalog enrichment is improving AI recommendation rates?
Track AI mention share by SKU, AI-referred session conversion rate, schema coverage score, and attribute completeness score by category. Standard analytics platforms do not surface these metrics - purpose-built AI visibility tools are required. Nudge surfaces SKU-level citation data across major AI shopping platforms, giving catalog teams a direct line from enrichment investment to recommendation share.
How long does it take to see AI recommendation improvements after enrichment?
Initial schema and attribute fixes can surface in AI Overviews within weeks of re-indexing. One retailer using GroupBy saw 50%+ CTR and 60%+ conversion improvements within a year of deployment. Sustained recommendation share requires ongoing enrichment and monitoring - not a one-time project. The brands building durable AI visibility advantages are those running continuous enrichment pipelines paired with SKU-level citation tracking.
