Catalog Optimization
Product Data Enrichment for AI Discoverability: The Ultimate Guide (2026)
Learn how to enrich product data so AI assistants like ChatGPT, Perplexity, and Google AI confidently recommend your SKUs. Actionable guidance for enterprise commerce teams.

Kanishka Thakur






Product data enrichment is the process of transforming raw or sparse product information into structured, accurate, channel-ready content so AI assistants can confidently identify, compare, and recommend the right SKU. Brands that skip this step are invisible to AI engines regardless of their Google rankings — audit data shows 54% of brands that rank well on Google are not cited by AI systems at all.
Why AI Assistants Are Now Your Most Important Shelf
AI shopping is not a future trend — it is the current channel. Between November and December 2024, traffic from generative AI sources increased 1,300% year-over-year, according to Adobe. During Cyber Week 2025, 20% of all global orders were influenced by AI agents or shopping assistants, according to Salesforce. ChatGPT alone processes 50 million shopping-related queries daily, and LLM traffic converts at 2.47% — above both Google and Meta Ads.
The stakes scale further when you consider the trajectory. Morgan Stanley predicts that nearly half of online shoppers will use AI shopping agents by 2030, accounting for roughly 25% of their spending. The global agentic commerce market, valued at $547.3 million in 2025, is projected to reach $5.2 billion by 2033. Over 1 million Shopify merchants have already opted into OpenAI's Instant Checkout feature, which enables autonomous purchasing directly within ChatGPT. The shelf has moved inside the conversation and enriched product data is how brands earn a spot on it.
What Is Product Data Enrichment and Why Does It Fail Today?
Product data enrichment transforms raw or sparse product information into structured, accurate, channel-ready content that helps AI systems confidently recommend the right SKU. Most enterprise catalogs fall short of this standard today, not by a small margin.
A McKinsey report drawing on insights from over 3,000 ecommerce companies found that product data errors cost up to 23% in clicks and 14% in conversions. A separate study assessing 510 SKUs across eight leading platforms found that 27% of SKUs fail on completeness alone and 23% fail on accuracy. The downstream impact is direct: 42% of shoppers abandon purchases when product information is incomplete, and nearly 2 in 5 online shoppers return items because the product did not match its listing.
The root causes are structural. Most enterprise catalogs still rely on supplier-provided CSVs, duplicate descriptions copied across variants, missing technical attributes, and product detail pages (PDPs) formatted for human browsing rather than AI parsing. Legacy feed management was built for distribution — pushing existing data to channels. AI discovery demands something deeper: enrichment that fills gaps, adds natural language context, and structures content so an LLM can extract and compare attributes in real time.
How AI Engines Actually Select and Recommend Products
AI engines do not rank products by domain authority or backlinks. ChatGPT selects products based on authoritative list mentions (41% of recommendations), awards (18%), and review volume (16%). Structured data quality — not SEO seniority — determines which SKUs get cited.
The data on structured content is unambiguous. A Data World study shows GPT-4 goes from 16% to 54% correct responses when content relies on structured data- a 3x accuracy jump from formatting alone. Properly structured content shows 73% higher AI selection rates compared to unmarked content, yet 89% of ecommerce sites currently implement SKU schema incorrectly. Freshness also matters: AI-surfaced URLs are 25.7% fresher than traditional search results on average, meaning stale PDPs are actively penalized in AI discovery.
The solution is an agentic catalog: a product catalog enriched and structured specifically for AI agent consumption, with protocol-compliant formatting, natural language descriptions, complete attributes, and real-time data access. This is the operational standard that separates brands AI cites from brands AI ignores. Learn more about SKU-level catalog optimization for AI and how the agentic catalog model works in practice.
The 5-Step Framework to Enrich Product Data for AI Discoverability
A repeatable enrichment workflow moves from raw data ingestion to AI-ready syndication in five sequential steps. Each step builds on the last skipping ahead produces incomplete catalogs that AI engines still cannot reliably parse.
Ingest and normalize raw data: Pull product data from all sources (PIM, supplier CSVs, ERP) into a single clean format. Standardize units, naming conventions, and category taxonomies.
Fill attribute gaps: Use AI-assisted enrichment to populate missing specifications, materials, compatibility data, certifications, and use-case context at the SKU level.
Write natural language descriptions: Generate SKU-specific, query-aligned descriptions that LLMs can parse — not generic copy duplicated across variants.
Implement structured data markup: Deploy Product + Offer + AggregateRating + BreadcrumbList + FAQPage + Organization schema on every PDP. Add an llms.txt file to guide AI crawlers.
Syndicate and maintain freshness: Push enriched data to all channels continuously, triggered by price, stock, or spec changes not monthly batch updates.
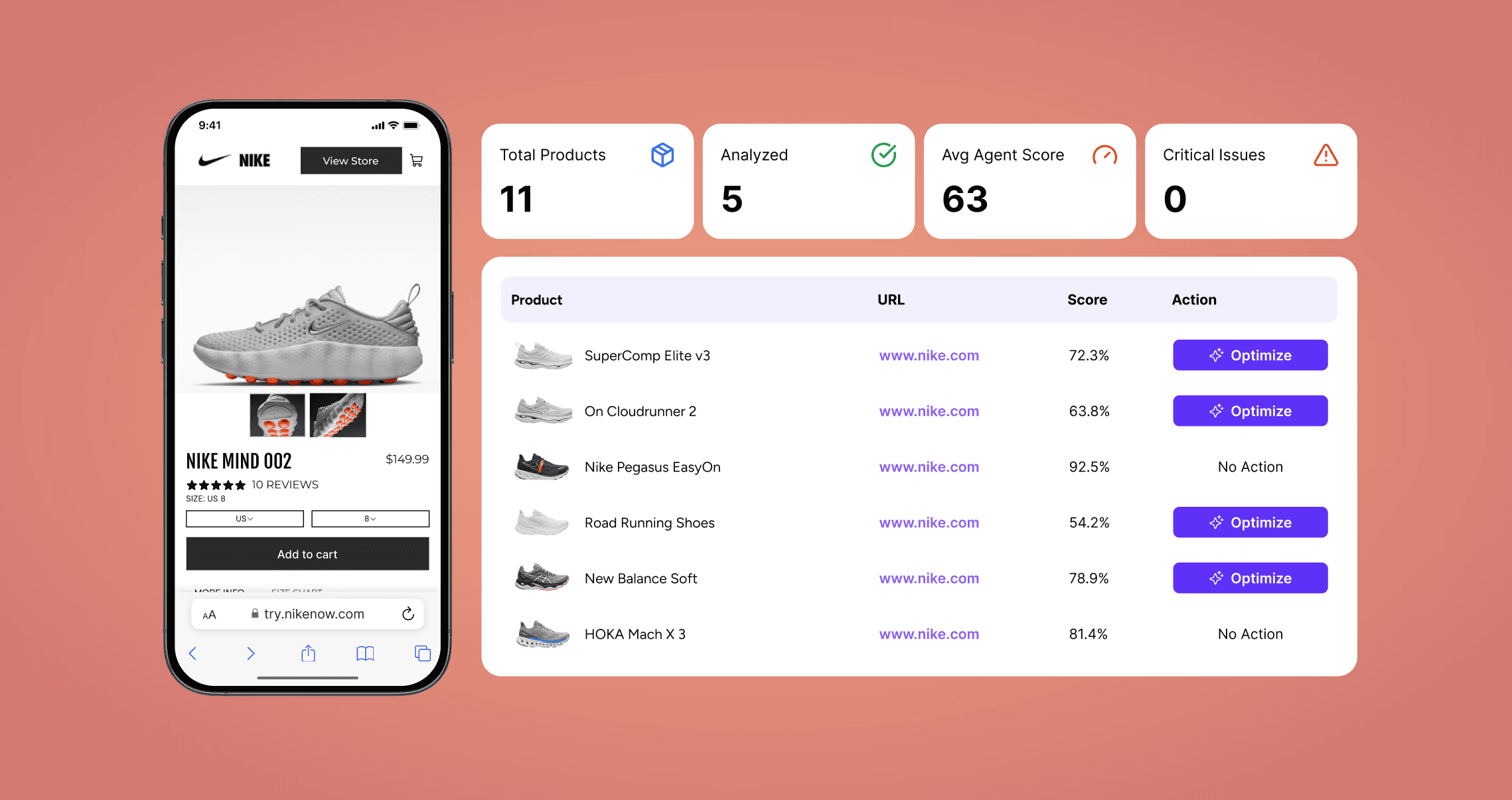
Legacy Feed Management vs. AI-Enriched Agentic Catalog
Dimension | Legacy Feed Management | AI-Enriched Agentic Catalog |
|---|---|---|
Attribute Completeness | Partial — supplier-provided fields only | Full — AI-filled specs, materials, compatibility, use-case context |
Schema Markup | None or basic Product schema | Product + Offer + AggregateRating + BreadcrumbList + FAQPage + Organization |
Natural Language Descriptions | Generic copy duplicated across variants | SKU-specific, query-aligned, LLM-parseable descriptions |
Freshness Cadence | Monthly or ad hoc | Continuous — triggered by price, stock, or spec changes |
AI Citation Rate | Low — 54% of top Google rankers get zero AI citations | High — structured content earns 73% higher AI selection rates |
LLM Guidance | robots.txt only | llms.txt deployed alongside robots.txt |
Which Attributes Matter Most for AI Recommendation Engines?
AI engines weight five attribute categories most heavily when selecting products to recommend. Completeness across all five is what separates cited SKUs from invisible ones.
Technical specifications: Materials, dimensions, weight, compatibility matrices, certifications — the structured facts LLMs use as source of truth.
Use-case context: Who the product is for, what problems it solves, and how it compares to alternatives — the natural language context AI uses for recommendation matching.
Social proof signals: Review volume, ratings, awards, and authoritative list mentions — ChatGPT weights these at 41% + 18% + 16% = 75% of recommendation decisions.
Availability and pricing: Real-time stock status, pricing tiers, and delivery parameters — stale data actively penalizes citation rates.
Media and visual assets: High-quality images, video, and alt text — these support both AI parsing and the conversion experience after citation.
The revenue case for completeness is direct. 62% of consumers say they are willing to spend more on a product that offers detailed information, according to GS1 US. Attribute completeness is not just an AI optimization — it is a conversion lever that pays off across every channel.
Measuring AI Discoverability: KPIs Your Team Should Track
Traditional rank tracking does not measure AI performance. A new KPI layer is required — one that tracks citation quality and prompt-level share of voice, not just organic position.
KPI | What It Measures | Why It Matters |
|---|---|---|
AI Citation Rate by SKU | How often each product is cited in AI responses to relevant prompts | Direct measure of enrichment effectiveness at SKU level |
Prompt-Level Share of Voice | Brand visibility across ChatGPT, Perplexity, and Google AI for target queries | Tracks competitive position in AI discovery, not just traditional SERPs |
LLM Referral Conversion Rate | Revenue generated from AI-referred traffic (benchmark: 2.47%) | Quantifies revenue impact of AI discoverability investments |
Attribute Completeness Score | Percentage of required attributes populated per SKU | Identifies highest-impact enrichment gaps before AI audits do |
Schema Validation Pass Rate | Percentage of PDPs passing structured data validation | 89% of ecommerce sites implement SKU schema incorrectly — this tracks the fix |
The disconnect from legacy SEO is structural: 47% of AI Overview citations come from pages ranking below position five in traditional search. A brand can hold the top three Google positions and still be absent from every AI-generated recommendation. That gap is what makes a dedicated AI discoverability measurement layer non-negotiable for enterprise commerce teams in 2025.
Nudge's catalog optimizer and AI search visibility platform operationalize these KPIs at catalog scale — tracking citation rate by SKU, prompt-level share of voice, and attribute completeness scores across enterprise catalogs, then connecting enrichment actions directly to conversion outcomes via shoppable prompt-aligned funnels.
Ready to Enrich Your Product Data for AI Visibility? Book a demo today!
Frequently asked questions
What is the difference between product data enrichment and product feed optimization?
Feed optimization focuses on formatting and distributing existing data to channels like Google Shopping. Enrichment goes deeper: filling missing attributes, adding natural language descriptions, and structuring data specifically so AI engines can parse and recommend the right SKU with confidence.
Which AI platforms benefit most from enriched product data?
ChatGPT (84.2% of AI referrals), Google AI Overviews, Perplexity, Amazon Rufus, and Microsoft Copilot all rely on structured, complete product data. Attribute completeness and schema markup improve performance across all of them.
How quickly can enriched product data impact AI citations?
AI-surfaced URLs are 25.7% fresher than traditional search results on average, meaning updated and enriched PDPs can be picked up within days of publication. Schema markup and llms.txt changes can influence AI crawling within one to two indexing cycles.
Do I need to enrich every SKU, or should I prioritize?
Start with your highest-revenue and highest-traffic SKUs, then expand. Research shows 27% of SKUs fail on completeness alone, so a completeness audit will surface the highest-impact gaps quickly. The Nudge catalog optimizer can automate prioritization at catalog scale.
How does product data enrichment relate to GEO (Generative Engine Optimization)?
GEO is the broader strategy of optimizing content for AI-generated responses; product data enrichment is the SKU-level execution layer. A Princeton University study found that targeted GEO strategies increase AI visibility by up to 40%. Enriched, structured product data is the foundation that makes those strategies work for commerce brands.

