Catalog Optimization
Product Schema Mistakes That Make SKUs Invisible to AI
The exact structured data errors blocking your product listings from ChatGPT, Perplexity, Google AI Overviews, and Gemini - and how to fix them at catalog scale.

Kanishka Thakur






Key Takeaways
A SALT.agency audit found 45% of top 100 ecommerce sites have zero structured data and 27% have schema errors, meaning 72% of major retailers are actively invisible to AI engines at the SKU level.
Schema markup alone is insufficient: AI systems ignore schema-only pages entirely; structured data must reinforce matching visible content to trigger citations in ChatGPT, Perplexity, and Google AI Overviews.
The five most damaging SKU-level schema mistakes are price mismatches, missing GTIN (confused with internal SKUs), placeholder brand values, absent review markup, and variant attributes placed on ProductGroup instead of individual Product entities.
71% of pages cited by ChatGPT and 65% cited by Google AI Mode include structured data, making correct Product schema the single highest-leverage technical fix for AI search visibility.
AI-referred shoppers generate 37% more revenue per visit than organic visitors, making SKU schema accuracy a direct revenue lever, not just a technical SEO task.
Most product schema errors are not validation failures - they are silent mismatches between what AI engines read in your structured data and what appears on the visible page, and that gap is why entire SKUs disappear from AI-generated recommendations. Fixing these errors is the single fastest path from catalog obscurity to AI-driven revenue.
Why AI Engines Cannot See Your Products Right Now
AI-referred traffic to U.S. retail sites grew 4,700% year-over-year in July 2025, and the shoppers arriving via those referrals are your most valuable: ChatGPT referral visitors convert at 4.4x the rate of organic search visitors, and revenue per visit from AI referrals runs 37% above non-AI traffic. Yet most catalogs are structurally invisible to the engines driving that traffic.
A SALT.agency audit of the top 100 ecommerce sites found 45% of product URLs contained no structured data at all, and another 27% had structured data with errors. That is 72% of major retailers actively failing the AI visibility test. Meanwhile, SE Ranking data shows 71% of pages cited by ChatGPT and 65% cited by Google AI Mode include structured data, confirming that correct Product schema is a prerequisite for citation, not a bonus.
SKU-level catalog optimization for AI means improving each product's metadata, structured data, copy, images, and catalog quality so AI systems like Rufus, Gemini, and ChatGPT can identify, match, and rank it accurately for discovery and purchase. The gap between 'valid schema' and 'AI-visible schema' is exactly where revenue disappears.
The 7 Product Schema Mistakes Killing Your AI Visibility
These seven errors account for the majority of SKU-level invisibility in AI search. Each one has a specific mechanism, a measurable impact, and a concrete fix.
# | Mistake | Broken Pattern | Correct Implementation | AI Impact |
|---|---|---|---|---|
1 | Price mismatch | JSON-LD shows $49.99; visible page shows $39.99 | Schema Offer price matches rendered page price exactly | Listing deprioritized or skipped entirely by AI engines |
2 | Internal SKU in GTIN field | gtin: 'SKU-00123' | gtin12/gtin13 contains a GS1-registered barcode | Google fails GS1 registry check; product may be disapproved |
3 | Placeholder brand values | brand: 'BrandNameHere' | brand: { '@type': 'Brand', 'name': 'Actual Brand Name' } | Entity disambiguation fails; product excluded from brand queries |
4 | Missing or thin review markup | No aggregateRating; zero reviews in schema | aggregateRating with ratingValue, reviewCount, and individual Review entities | Products with fewer than 5 reviews have 270% lower purchase likelihood |
5 | Variant attributes on ProductGroup | size, color, price on ProductGroup entity | Variant-specific attributes on individual Product entities inside hasVariant | AI cannot resolve which variant matches the shopper query |
6 | Stale Offer schema | Price/availability cached from yesterday's batch | Real-time refresh; OpenAI agentic spec expects updates as often as every 15 minutes | AI surfaces wrong price or out-of-stock item; trust erodes |
7 | Client-side rendering | Schema injected via React/Vue after page load | Server-side or static rendering so schema is in initial HTML response | 69% of AI crawlers cannot execute JavaScript; they see a blank page |
A few of these deserve deeper context. On mistake two: your internal stock-keeping unit is not a GTIN. SKUs are specific to your business; GTINs are globally standardized identifiers registered with GS1. Submitting a SKU in the GTIN field causes Google to fail verification against the GS1 registry, potentially leading to product disapproval or account suspension. On mistake six: OpenAI's agentic checkout spec expects price and availability to refresh as often as every 15 minutes. Stale Offer schema is a leading cause of AI engines surfacing incorrect product information or skipping listings entirely.
What Catalog Anemia Is Costing You at the SKU Level
Catalog Anemia is the condition where a merchant's feed is structurally present but functionally empty: the average retailer is absent from over 70% of possible attribute fields, with material, pattern, and product description 100% blank in many cases. The result is not just lower rankings - it is active mismatching.
One real-world example illustrates the problem precisely: a four-person tent surfacing in results for a two-person tent query because the SKU mapping was wrong, and the brand had no idea. That is Catalog Anemia in action. AI engines match on the attributes you provide; if those attributes are absent or incorrect, the engine substitutes the closest available data and gets it wrong.
A February 2024 Nature Communications study confirmed that LLMs extract information more accurately from structured, defined fields versus unstructured instructions. This means the specific attributes you populate in schema directly determine how accurately AI engines represent your products. The fields most commonly missing - and most urgently needed - are:
material - fabric, finish, or composition that differentiates variants
pattern - print, texture, or design type for apparel and home goods
product description - a complete, query-matching text block (not a truncated title)
color - standardized color names, not internal codes like COL-007
size - with explicit size system notation (US, EU, UK)
GTIN - GS1-registered identifier, never an internal SKU
Schema Reinforces Content - It Cannot Replace It
Schema-only pages are completely ignored by ChatGPT, Gemini, Claude, and Perplexity. This is the most important misconception to correct: structured data is a reinforcement signal, not a replacement for visible content.
The mechanism works in three layers. Schema communicates entity definition (which specific SKU exists and what type of thing it is), attribute clarity (current price, availability status, aggregate rating), and entity relationships (offeredBy, sameAs, brand). When schema values match what is visible on the page, AI engines treat the data as confirmed and cite it with confidence. When they conflict, the listing is flagged as unreliable.
Both Microsoft and Google have confirmed this publicly. Fabrice Canel, principal product manager at Microsoft Bing, confirmed in March 2025 that schema markup helps Microsoft's LLMs understand content for Copilot. Google stated in April 2025 that structured data gives an advantage in AI search results. These are not SEO best-practice recommendations - they are direct confirmations from the teams building the AI citation systems your products need to appear in.
The data on citation rates reinforces this: properly structured content shows 73% higher AI selection rates compared to unmarked content, and pages combining text, images, video, and structured data see 156% higher AI selection rates. Schema is the anchor; content is the structure it holds in place.
ProductGroup, Variants, and the Schema Hierarchy AI Engines Expect
For variant products, the correct architecture uses ProductGroup with three specific properties: variesBy (which attributes differentiate variants), hasVariant (linking to each individual Product entity), and productGroupID (a stable identifier for the parent group). Variant-specific attributes - size, color, price, and availability - belong on individual Product entities, not on the ProductGroup itself.
This is not a minor structural preference. Placing variant-specific attributes on the ProductGroup parent means AI engines cannot resolve which specific variant matches a shopper's query. A search for 'blue size 10 running shoe' against a ProductGroup that lists all colors and sizes together returns ambiguous results. Implementing ProductGroup schema correctly produced a 12.71% average increase in clicks across client setups and industries.
Looking ahead, the agentic commerce layer adds a new dimension to schema requirements. Google launched the Universal Commerce Protocol (UCP) and OpenAI shipped a major ChatGPT Shopping upgrade running on the Agentic Commerce Protocol (ACP). Merchants with dual UCP/ACP implementation are capturing 40% more agentic traffic than single-protocol stores. Teams should also note that Google deprecated FAQ schema in January 2026 and HowTo schema in February 2026 - do not invest engineering time in schema types that no longer deliver rich results.
How to Audit and Fix SKU Schema at Scale
Enterprise catalog teams need a repeatable audit process, not a one-time fix. Schema errors regenerate as catalogs update, prices change, and new variants are added. Here is the five-step framework:
Crawl for missing structured data. Use Google Rich Results Test and third-party crawl tools to identify product URLs with no schema, invalid schema, or schema that fails to match visible page content. Prioritize high-revenue SKUs first.
Validate GTIN fields against the GS1 registry. Any GTIN that fails GS1 verification is either an internal SKU submitted in error or a placeholder. Both must be corrected before AI engines will trust the listing.
Check price and availability staleness. Compare schema Offer values against live page content at crawl time. Gaps of even a few hours create the price mismatch pattern that causes AI engines to deprioritize listings.
Audit robots.txt and CDN rules for LLM crawler blocks. Approximately 27% of ecommerce sites are accidentally blocking major LLM crawlers due to CDN-level rules. Check that GPTBot, ClaudeBot, PerplexityBot, and Google-Extended are not blocked.
Confirm server-side rendering for all product pages. If product pages rely on client-side rendering via React, Vue, or similar frameworks, AI bots see a blank page regardless of schema quality, because 69% of AI crawlers cannot execute JavaScript.
Monitor SKU Schema Health at Catalog Scale with Nudge
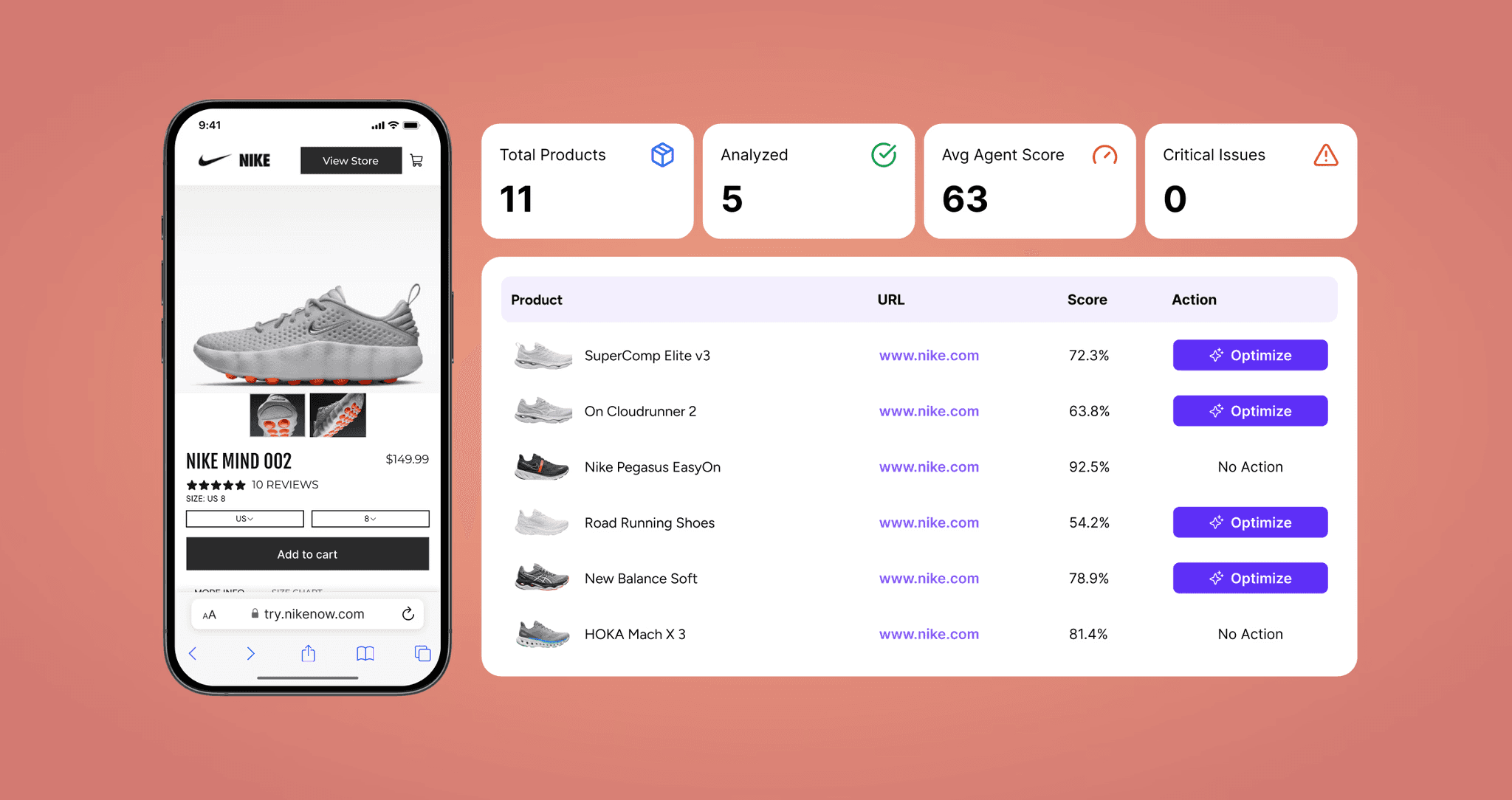
For catalogs running millions of SKUs, manual audits are not operationally viable. Nudge's catalog optimizer continuously monitors schema health across your entire product catalog, flagging price mismatches, GTIN errors, missing attributes, and rendering issues before they cost you AI citations. The AI search visibility platform connects schema health directly to citation tracking across ChatGPT, Perplexity, Google AI Overviews, and Gemini - so you can measure the revenue impact of every fix, not just the technical compliance score. Fixing schema is the entry point, but AI-referred traffic must land on prompt-aligned shoppable funnels to convert at the rates the data promises. Nudge connects both layers end to end!
Frequently asked questions
What is the most common product schema mistake that blocks AI search visibility?
Price mismatch between the visible page and the JSON-LD Offer schema is the most common and damaging error. AI engines surface the schema value, and when it conflicts with page content, the listing is deprioritized or ignored entirely. Auditing for price staleness should be the first step in any schema remediation project.
Does valid schema guarantee my products appear in ChatGPT or Google AI Overviews?
No. Schema must reinforce matching visible content. Controlled tests show schema-only pages are completely ignored by ChatGPT, Gemini, Claude, and Perplexity. Passing Google Rich Results Test validation is necessary but not sufficient for AI citation. The visible page content must state the same facts the schema encodes.
What is the difference between a SKU and a GTIN, and why does it matter for AI?
A SKU is an internal stock-keeping identifier specific to your business. A GTIN is a globally standardized identifier registered with GS1. Submitting an internal SKU in the GTIN field causes Google to fail verification against the GS1 registry, which can lead to product disapproval. AI engines rely on GTIN for entity disambiguation across the web - without a valid GTIN, your product cannot be matched to external signals like reviews or price comparisons.
How often should Offer schema (price and availability) be updated for AI engines?
OpenAI's agentic checkout spec expects price and availability data to refresh as often as every 15 minutes. Stale Offer schema is a leading cause of AI engines surfacing incorrect product information or skipping listings entirely. For enterprise catalogs, this requires automated schema generation tied to live inventory and pricing systems, not batch exports.
Where should size, color, and price be placed in a ProductGroup schema structure?
Variant-specific attributes including size, color, price, and availability must be placed on individual Product entities within the ProductGroup, not on the ProductGroup itself. Placing them on the parent is one of the most common structural errors in ecommerce schema. The ProductGroup should only carry shared attributes like brand, name, and productGroupID.

